比较k折交叉验证法与留一法。本题采用UCI中的 Iris Data Set 和 Blood Transfusion Service Center Data Set,基于sklearn完成。
本文编程采用Python-sklearn实现,相关源码托管于Github:PnYuan/Machine-Learning_ZhouZhihua,欢迎访问。
题目
本题采用UCI中的 Iris Data Set 和 Blood Transfusion Service Center Data Set,基于sklearn完成练习(查看完整代码和数据集)。
关于数据集的介绍:
IRIS数据集简介 - 百度百科;通过花朵的性状数据(花萼大小、花瓣大小…)来推测花卉的类别。变量属性X=4种,类别标签y公有3种,这里我们选取其中两类数据来拟合对率回归(逻辑斯蒂回归)。
Blood Transfusion Service Center Data Set - UCI;通过献血行为(上次献血时间、总献血cc量…)的历史数据,来推测某人是否会在某一时段献血。变量属性X=4种,类别y={0,1}。该数据集相对iris要大一些。
具体过程如下:
数据预分析
iris数据集十分常用,sklearn的数据包已包含该数据集,我们可以直接载入。对于transfusion数据集,我们从UCI官网上下载导入即可。
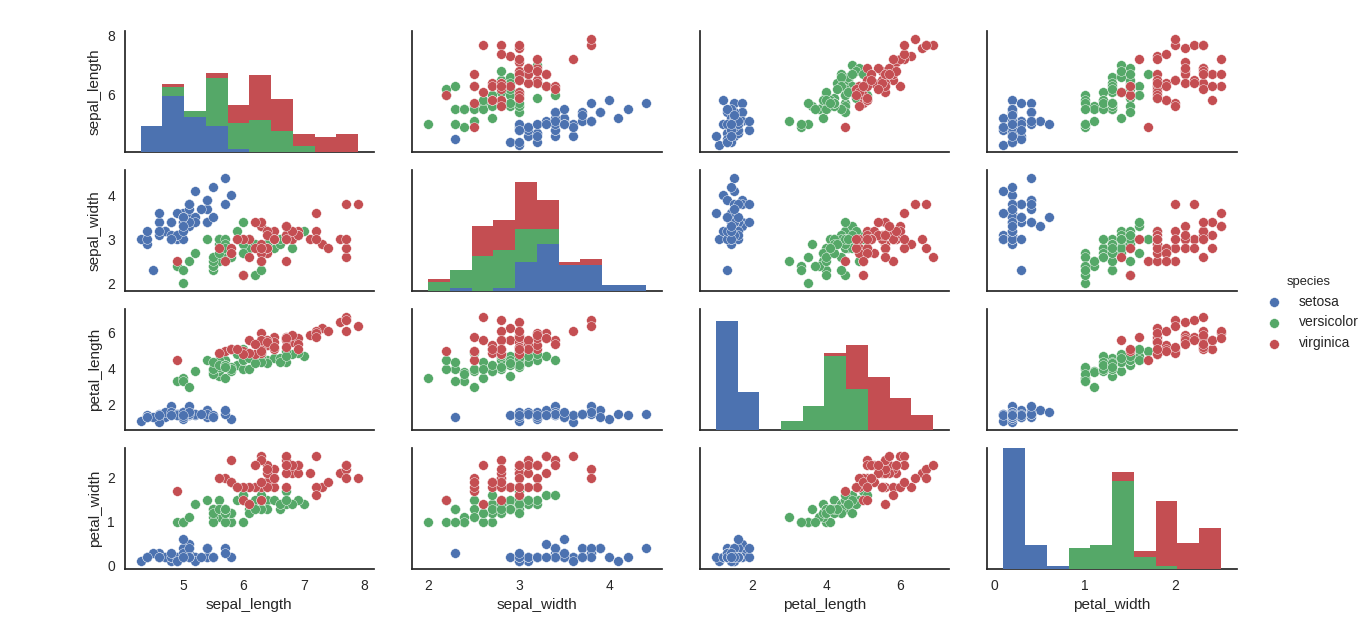
采用seaborn库可以实现基于matplotlib的非常漂亮的可视化呈现效果,下图是采用seaborn.pairplot()绘制的iris数据集各变量关系组合图,从图中可以看出,类别区分十分明显,分类器应该比较容易实现:
相关样例代码:
1 | import numpy as np |
基于sklearn进行拟合与交叉验证
这里我们选择iris中的两类数据对应的样本进行分析。k-折交叉验证(1<k<n-1)可直接根据sklearn.model_selection.cross_val_predict()得到精度、F1值等度量。留一法稍微复杂一点,这里采用loop实现。
面向iris数据集的样例代码:
1 | ''' |
得出了精度(预测准确度)结果如下:
0.97
0.96
可以看到,两种方法的模型精度都十分高,这也得益于iris数据集类间散度较大。
同样的方法对blood-transfusion数据集得出的精度结果:
0.76
0.77
也可以看到,两种交叉验证的结果相近,但是由于此数据集的类分性不如iris明显,所得结果也要差一些。同时由程序运行可以看出,LOOCV的运行时间相对较长,这一点随着数据量的增大而愈发明显。
所以,一般情况下选择K-折交叉验证即可满足精度要求,同时运算量相对小。