下面,我们结合Kaggle赛题:Avazu:Click-Through Rate Prediction,练习数据挖掘技术在CTR预估中的应用。
本文内容包括赛题任务简析,以及基于LR(逻辑斯蒂回归)的初步实现。

本文的源码托管于我的Github:PnYuan - Kaggle_CTR,欢迎查看交流。
1.任务概述
CTR(Click Through Rate,点击率),是“推荐系统/计算广告”等领域的重要指标,对其进行预估是支持进一步地“商品推送/广告投放”等决策的基础。Avazu:Click-Through Rate Prediction是Kaggle2015举行的一场CTR预估比赛。赛事主办方提供了规约化的历史数据(train.csv)与待预测数据(test.csv),下述条目给出了该赛事任务的一些基本信息:
任务输入:数据集文件:train.csv 和 test.csv。
任务输出:给出预测集id所对应的CTR预估值,形如:
id, click xx01, 0.118.. xx02, 0.159.. xx03, 0.162..评价方法:log-loss,二分类任务的交叉熵损失函数;
原始数据规模(百万级样本数):
训练集样本数:≈40.4M 测试集样本数:≈4.58M原始特征(20+),有关特征的官方解释见赛题主页-Data,下面示意性列举了部分特征:
id: int或string型,用户ID号,可作为样本索引; click:bool或int型,只存在于训练集中,样本的标签(是否点击:0-否,1-是); hour:int型,时间变量形如YYMMDDHH; C1:int型,匿名特征; banner_pos:int型,网页上的广告位置,离散特征0,1,2,3... app_id:string型,用户APP的ID; ...
据上所述,可以为该任务贴上一些初识标签,如:有监督学习、二分类概率预测、较大规模数据等等。
2.特征工程
本文拟给出一个基于LR的任务初步实现样例,主要目的是体验CTR预估的任务进行过程。在训练LR模型之前,首先要根据原始数据特点以及模型输入要求,对原始特征数据进行预处理以使更好的用于模型的训练与上线。
赛题主页-Data页对原始数据及其特征进行了简要说明。这里为简化计算过程,只选用部分原始特征进行实验,如下表所示:
| 特征名 | 数值类型 | 数值样例 | 特征内涵 |
|---|---|---|---|
| C1 | int | 1001,1004 | 未知 |
| banner_pos | int | 0,1,2… | 广告条目位置 |
| site_domain | str | f3845767,1b32ed33… | Site领域 |
| site_id | str | 1fbe01fe,fe8cc448… | Site ID |
| site_category | str | 28905ebd,0569f928… | Site类型 |
| app_id | str | ecad2386,98fed791… | App ID |
| app_category | str | 07d7df22,cef3e649… | APP类型 |
| device_type | int | 0,1,2… | Device类型 |
| device_conn_type | int | 0,1,2… | Device接入类型 |
| C14 | int | 20366,19251… | 未知 |
| C15 | int | 320,120… | 未知 |
| C16 | int | 50,250… | 未知 |
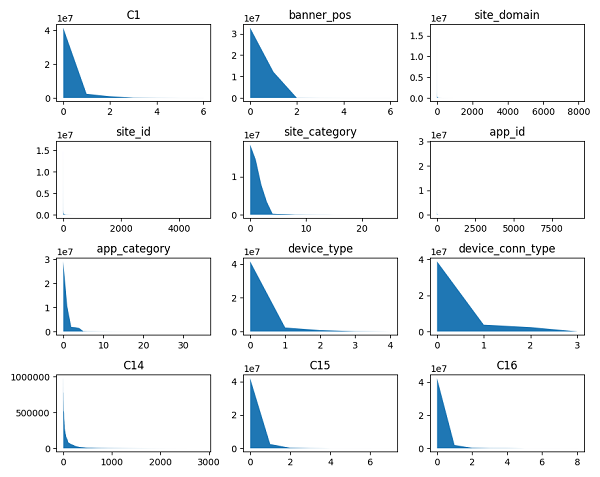
原始特征绝大多数为离散类别型(categorical)(包括上表所选特征在内)。当采用此类特征进行LR训练时,常进行独热编码(One-Hot Encoding)以使其数据更加利于模型学习。这里由于部分特征的类别取值数量巨大,全部采用One-Hot编码易产生高维度稀疏矩阵,影响学习效率,考虑到特征类别取值呈现长尾分布,如下图所示,故而先将稀有类别取值统一设置为“Other”,然后再进行One-Hot编码处理,从而在保留主体特征信息的同时,控制新特征维度,提高训练效率。
考虑到数据规模较大,这里采用dummyPy工具包来分块实现数据的One-Hot转换。
3.LR实验
LR(逻辑回归/对率回归)模型是一个非常简单实用的有监督学习模型,这里我们将其运用到对CTR预估的初步尝试中。考虑到数据量较大,这里我们采用sklearn.linear_model.SGDClassifier库函数来实现LR的增量式学习。通过设置默认的SGDClassifier超参数,采用分块式训练,得出训练过程损失(log-loss)曲线如下图所示。
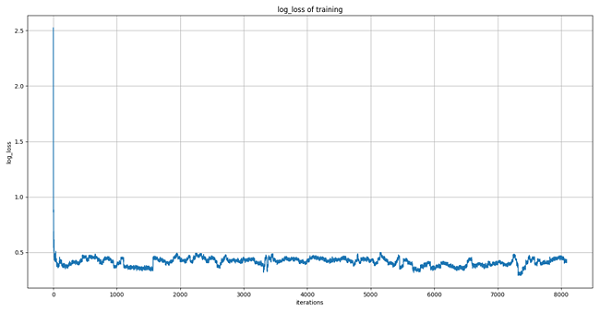
初步分析曲线收敛状况可知,训练过程损失指标始终处于log-loss=0.4左右微振荡。猜测LR模型已大致完成对当前数据的拟合,但效果欠佳。采用经此训练的模型进行预测,得出结果提交至Kaggle评分为:
- private:0.4172740 (rank 75%)
- public: 0.4155279 (rank 74%)
之后,我们尝试引入更多的原始特征进行LR实验,获得了一定的结果提升,如:
- private:0.4097192 (rank 72%)
- public: 0.4118247 (rank 72%)
4.小结
本文围绕Avazu-CTR预估任务,以LR-based为基本方案,相继完成了:
- 任务和数据的解析;
- 原始特征抽取及其One-Hot编码预处理;
- LR训练及预测;
三部分的内容,取得了初步的评分结果。之后还可以在模型的选择与改进、特征工程的细致深入、训练调优策略的积极尝试等方面入手,进一步研究提高CTR预估效果。