本文继续以Avazu-CTR赛题为场景,采用GBDT(梯度提升树)与LR(逻辑回归)相结合的方法来完成CTR预估任务;
本文的源码托管于我的Github:PnYuan - Kaggle_CTR,欢迎查看交流。
1.GBDT-LR方案
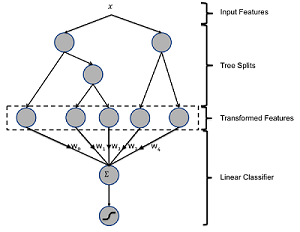
集成模型如GBDT、XGBoost等,可被用于原始特征的转换与组合,从而自动构建出新的特征用于改进数据挖掘任务。这里,我们采用业界常用的GBDT-LR方案来完成CTR预估任务,其中GBDT的作用正如上所述。整个方案的模型示意图如下:
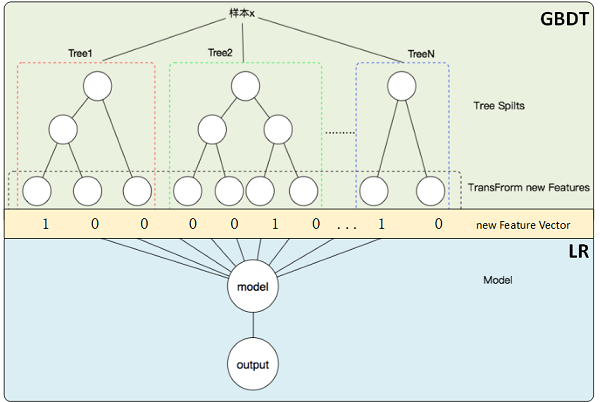
这里,GBDT的所有输出叶子节点构成新特征向量(上图中Transform new Features),每条原始数据样本可由GBDT转化为新的数据条目(上图中new Feature Vector)。经过良好训练后的GBDT,可视为一系列优质特征处理规则(转换、组合、过滤…)的复合,最终实现的是新旧特征的映射,进而使得原始数据经其处理后,更加有利于LR等模型的学习训练。
进一步解析GBDT-LR方案的好处如下:
GBDT作为一种Boosting集成模型,其建模过程以残差拟合为目的,相应的数据信息学习也是从主体到细节(到噪声)。于是,对于GBDT序列化的子模型,其叶节点索引所对应的新特征的重要性是递减的,这事实上为我们提供了一套特征排序
GBDT实现了显示的特征转换,通过设置合理的子模型数量,既保留数据主体信息,又控制特征空间维度,提高数据效用和训练效率;
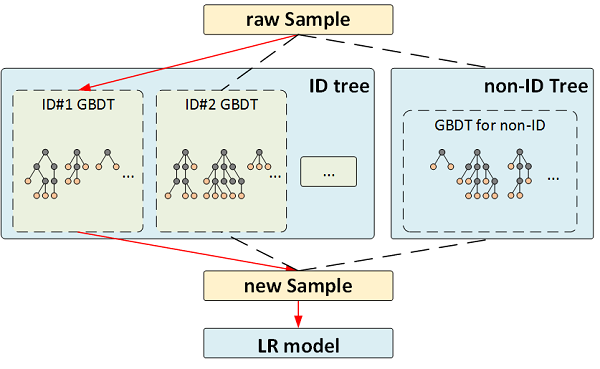
在广告推荐中,广告ID是一个易被忽略的重要特征。采用GBDT-LR的方案可将其很好的利用起来。一般而言,ID取值多且呈现长尾分布,常用作法是对一些大广告(曝光充分,样本充足)建立专属GBDT,其它构建共用GBDT,其思路如下图示:
本文,我们先训练一个GBDT来完成上层特征处理任务,然后采用LR模型完成CTR的预估。
2.特征工程
这里,我们选取与上文CTR预估(LR)相同的原始特征(共计12个),同样进行长尾简化(rare to ‘Other’),在模型的训练和预测过程中,还需对数据进行如下处理:
标签编码
原始特征数据取值均为离散类别型(categorical),针对GBDT模型,考虑将原有数据进行数值标签转换,如采用
sklearn.preprocessing.LabelEncoder。独热编码
有些工具包的GBDT输出为叶节点索引(如
sklearn.ensemble.GradientBoostingClassifier),为利于进一步的LR模型使用,还需考虑将其进行One-Hot编码,如采用sklearn.preprocessing.OneHotEncoder。
3.CTR预估实验
3.1.数据生命周期检查
为进一步理解GBDT-LR的运行过程,同时排查编程实现的错误。这里对整个过程中的数据形态变化进行检视。数据的处理流程为:
原始特征数据 -> 标签编码 -> GBDT -> 独热编码 -> LR -> 输出。
其各环节的数据内容形态记录如下:
基于
GradientBoostingClassifier实现GBDT。这里我们进行下采样来简化训练集规模(从原始训练集中随机抽取2M条样本),得出训练数据如下所示(shape as [n_samples=2M, n_features=12]):
基于
LabelEncoder对原始数据进行标签编码,得出数值化数据如下所示(shape as [n_samples, n_features = 12]):
上述数据经GBDT处理后,输出为每个叶子节点的索引,如下图所示(
shape as [n_samples, n_features = n_estimators, n_classes=1]):
对GBDT输出数据进行One-Hot编码,得出LR的输入数据,为稀疏矩阵(
shape as [n_samples, n_features = n_leaves(GBDT叶子节点总数)]),数据描述如下:>>> X2_train_lr <35000x1724 sparse matrix of type '<class 'numpy.float64'>' with 700000 stored elements in Compressed Sparse Row format> >>> X2_train_lr[0] <1x1724 sparse matrix of type '<class 'numpy.float64'>' with 20 stored elements in Compressed Sparse Row format> (这里GBDT子树个数为20,叶子节点总数为1724)(略)
3.2.模型训练调优
此处模型包括GBDT与LR两部分,均可采用sklearn相应库函数来编程实现,下面给出建模、训练过程中的一些技巧:
将原始训练集划分为训练集(
train)和验证集(valid),其中训练集又继续一分为二分(train_gbdt,train_lr)别用于GBDT和LR的训练以防止过拟合。GBDT的超参数如
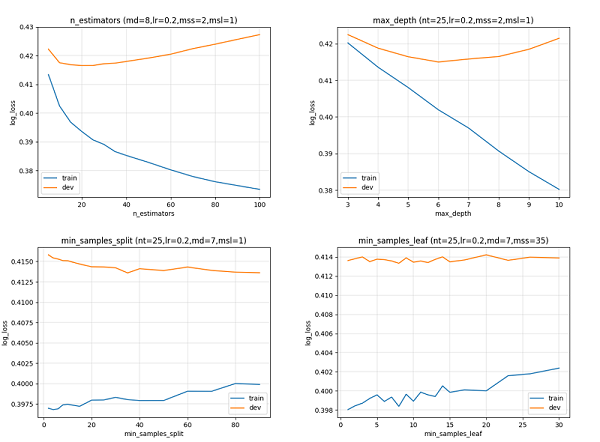
n_estimators、max_depth、min_samples_split等直接关乎模型效果,对其进行调节要综合计算能力限制、拟合效果平衡、输出维度考量等多方面,推荐采用采用启发式寻优。
下图展示了本次实验中GBDT参数调节对结果的影响,其中训练集(train)和测试集(dev即valid)间的分差反应了GBDT的过拟合程度。
3.3.预测CTR
采用预训练后的GBDT-LR模型处理测试集,将得出的预测结果上传至Kaggle评分为:
- Private Score: 0.4036965(69%)
- Public Score: 0.4056284(69%)
4.小结
本文给出了GBDT-LR_based CTR的方案,包括:
- GBDT用于自动特征映射的相关理论;
- GBDT-LR模型结构;
- 基于GBDT-LR的CTR预估实验;
几个部分。与前文对比可知,CTR预估场景采用堆叠模型(GBDT-LR)更易取得好的结果。