本文以自动驾驶场景下的对象检测(Object Detection)为研究对象,学习理解滑窗卷积和YOLO等内容。

1.对象检测
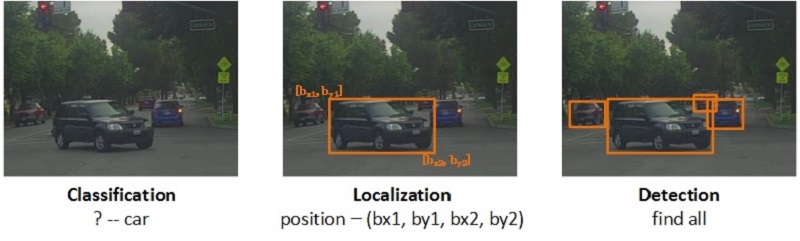
对象检测(Object Detection)的目的是”识别对象并给出其在图中的确切位置”,其内容可解构为三部分:
- 识别某个对象(Classification);
- 给出对象在图中的位置(Localization);
- 识别图中所有的目标及其位置(Detection)。
如下图所示,从左到右分别展示了:某个对象的识别(P(目标)=1,class=car),对象在图中的定位(给出边框bounding box–<bx1,by1,bx2,by2>),图中所有考察对象的识别与框定。
2.滑窗+CNN
滑动窗口(Sliding Windows,简称滑窗)法是进行目标检测的主流方法。对于某输入图像,由于其对象尺度形状等因素的不确定性,导致直接套用预训练好的模型进行识别效率低下。通过设计滑窗来遍历图像,将每个窗口对应的局部图像进行检测,能有效克服尺度、位置、形变等带来的输入异构问题,提升检测效果。下图展示了某种大小的滑窗在待检测图像上滑动的过程:

下图展示了采用滑窗(size=8×8, stride=2)对图片(10×10)进行对象检测的全过程示意。图示的输出为2×2的网格,每个格子对应一个输出标签向量,给出了原图对应的窗口区域图像的检测结果(置信度、边框位置、各类别概率等)。
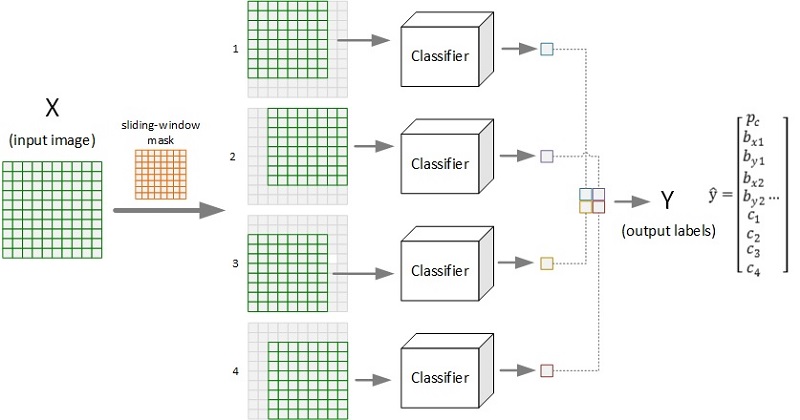
要实现对象检测,需要有相应的目标识别模型(如上图中的Classifier),卷积神经网络(CNN)是其中的主流模型之一。但是,按照上图所示,采用CNN对每个窗口图像进行检测,会产生大量的重复计算(如卷积操作),为了提高检测效率,通过合理设计CNN模型,可以仅需一次前向传播而得出整个图像的滑窗检测结果。下图展示了相关的模型设计实现过程:
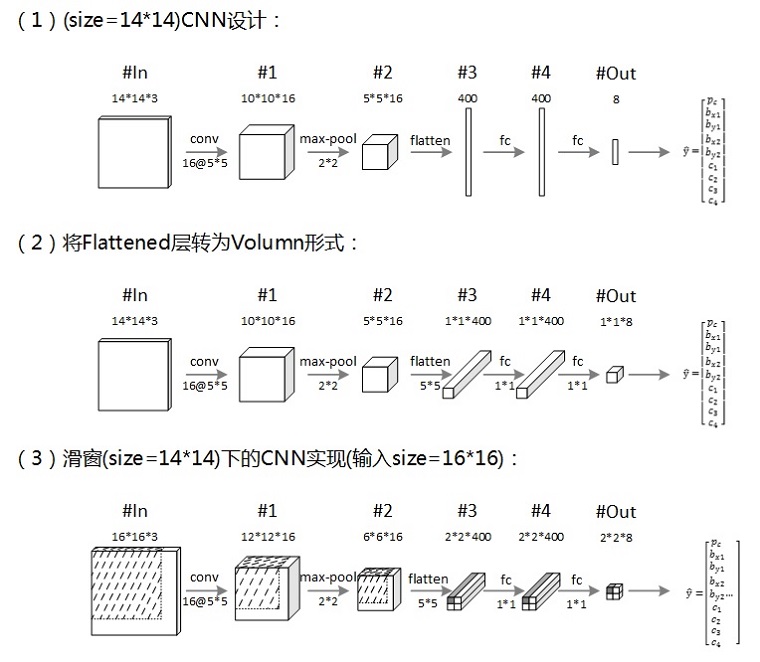
上图的三步描述了采用14×14大小的窗口进行滑动卷积时的CNN设计实现过程。采用(2)所设计的CNN对(3)中的输入图像进行检测,可以一次性得出最终的结果网格,其相应位置的网格映射了滑动窗口在原图像上的相应区域(如图中输出2×2网格左上角向量即为第一个窗口的CNN检测结果,图中的阴影标注了该窗口信息在CNN中的流动)。
3.YOLO
YOLO(You Only Look Once),是一种端到端(end-to-end)的对象检测方法。虽然是端到端模型,其实也可以粗略地分解为回归预测与边框筛选两部分。首先,采用回归模型(如滑窗CNN)一次得出全图像的边框标注,同时将图像进行网格化分,每个格子负责中心点落于其上的对象的边框(boxes);然后,采用非最大抑制基于每个格子得出经过筛选之后的边框输出。该过程示意如下:
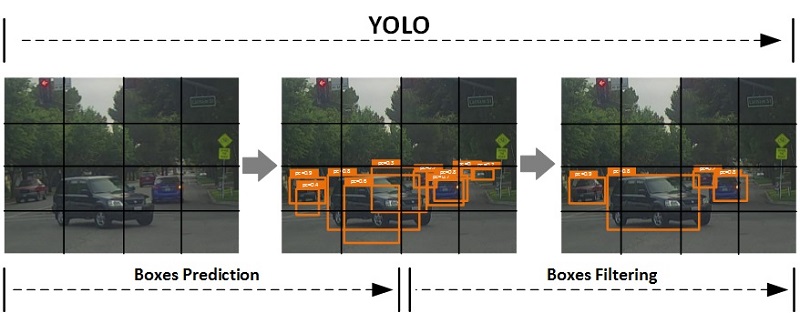
上图中,标注预测(Boxes Prediction)环节负责得出大量候选边框,该部分可采用的模型多种多样(如上文介绍的滑窗CNN);边框筛选(Boxes Filtering)过程则采用非最大抑制来实现。这里先给出YOLO边框筛选的两个重要基础概念:交并比(IoU)与非最大抑制(NMS)。
交并比(Intersection over Union,IoU)
交并比用来描述两个边框(bounding boxes)的重合程度,其定义为:
IoU = (S1∩S2)/(S1∪S2),即两框覆盖区域的交集与并集的面积比。IoU越大,说明两个边框重合度越高。非最大抑制(Non-Max Suppression,NMS)
非最大抑制的基本思想是,对于表示同一个对象的多个边框,仅保留其中置信度最大的框,而将其他筛除。该筛选过程可描述如下:
设每个输出形式为: boxes = [pc,bx1,by1,bx2,by2,…]
- 去掉
pc ≤ 阈值的boxes; - 若还有
boxes剩余:(1)选出其中pc->max的边框作为预测并输出;(2)去掉与该boxes相交的满足IoU ≥ 阈值的所有边框; - 重复
2.直到没有boxes剩余,由此得出所有的预测输出boxes。
- 去掉
YOLO的边框筛选过程可举例描述为:如经过滑窗CNN检测后,每个输出网格(cell)负责检测出中心点落在其中的多个边框(boxes),然后采用非最大抑制对这些边框中属于同一类的进行筛选,从而得出最终的输出结果。
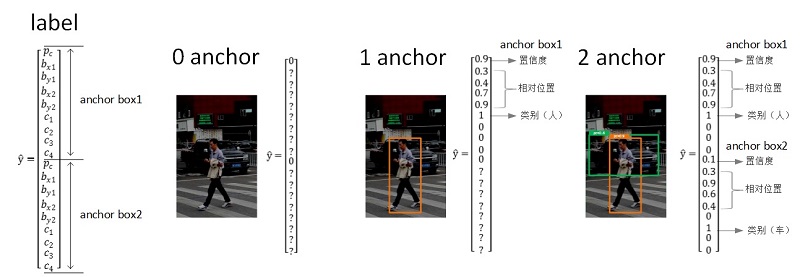
另外在YOLO中,还可以通过设置anchor boxes来实现对多个重叠的不同类边框的有效检测。如下图所示,设置 2 anchors 实现两种对象重叠情况的检测。
4.实验
这里我们直接采用YOLO官网所提供的预训练好的模型来进行检测实验尝试,下面展示了一些检测结果(测试图像取景自华小科校内):




可以看出,直接采用互联网资源所提供的预训练模型即可实现很不错的检测效果。在此基础上,可通过采集更加丰富的目标场景图像数据,在现有模型上进行迁移学习,以期实现更好的面向具体应用的检测模型。